[상황]
서버 배포 시 아래의 에러 내용을 확인하였습니다.
AbortError: Redis connection lost and command aborted. It might have been processed.
at RedisClient.flush_and_error (/var/app/current/node_modules/redis/index.js:362:23)
그리고 ElastiCache의 현재 연결 갯수 지표에서,
배포 시점에 read replica의 연결이 끊어졌다가 다시 붙는걸 확인했습니다.

[원인]
1. Elastic BeansTalk 구성 - 추가 배치를 이용한 롤링 배포로 인한 ElastiCache 부하 증가

API서버의 경우 평균적으로 23대의 인스턴스가 실행 중이고,
서버 배포 시, 추가 배치를 사용한 롤링 비율이 75%로 설정되어 있습니다.
해당 설정으로 인해 서버 배포 시 17개의 인스턴스가 한번에 생성되고 있습니다.
아래의 지표를 통해
배포 시점에 ElastiCache의 현재 연결 갯수가 크게 증가하고, 네트워크 송신 대역폭 초과가 발생하는 것을 확인할 수 있습니다.
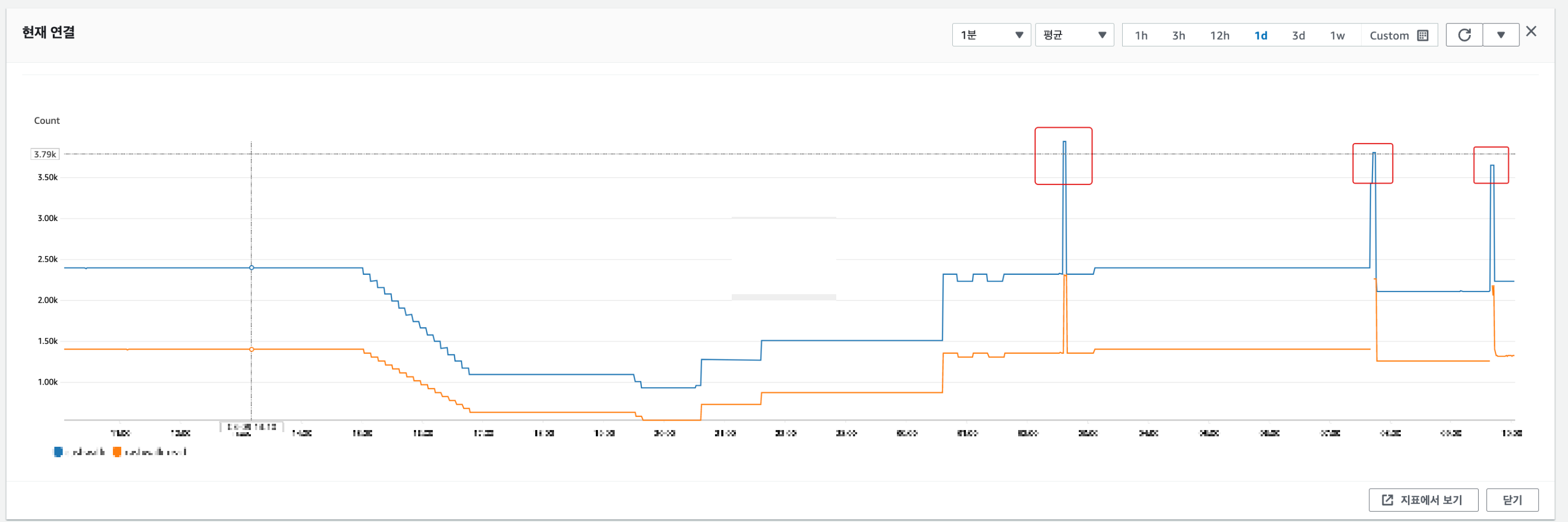

여기서 눈여겨 봐야할 부분은
총 3번의 배포에서 1번째 배포에서는 현재 연결이 끊어지지 않고, 2번째 3번째 배포에만 장애가 발생했다는 점입니다.
어떤 차이가 있는지 확인하기 위해 다른 지표들을 찾아보다가,
2번째 배포가 되던 시점부터 swap 메모리가 급증한 것을 확인했습니다.
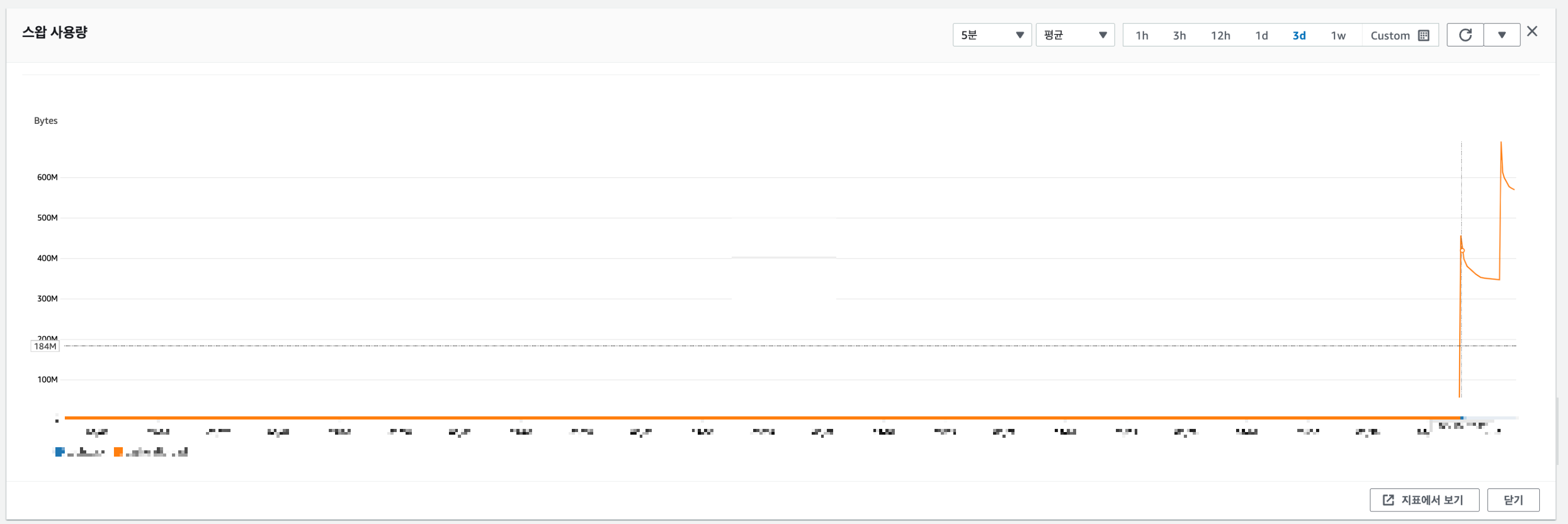
2. Swap 메모리 사용 원인
swap 메모리가 사용되는 경우는, ElastiCache의 메인 메모리의 용량이 부족한 경우입니다.
AWS 공식 문서에 따르면,
네트워크 대역폭 병목이 발생하면 버퍼 사용량이 계속 누적될 수 있고, 이로인해 메모리가 고갈되어 성능이 저하된다고 합니다.

1번과 연관 지어서 생각해보면,
배포 시점에 새로운 인스턴스가 급증하여 ElastiCache에 대량의 요청이 발생하였고,
네트워크 송신 대역폭을 초과로 인해 네트워크 대역폭 병목이 발생했으며
버퍼 사용량이 계속 누적되다가 특정 시점에 메모리가 고갈되어서 Swap 메모리가 사용된 것으로 보입니다.
3. 결론
Swap 메모리가 사용되면서 ElastiCache의 성능이 저하됐고,
그로 인해 일시적으로 정상 동작하지 않은 것으로 보여집니다.
다만, 성능의 저하로 인해서 연결 자체가 끊기는 부분은 아직 정확하게 알아내지 못했습니다.
이 부분은 명확하게 알아내면 추가로 작성할 계획입니다.
[대응]
1. 서버 배포 시 롤링 비율 수정하기
75%였던 비율을 30%로 줄여서, 배포 시점에 동시에 많은 인스턴스가 생성되는 것을 방지했습니다.
2. 네트워크 송신 대역폭 초과를 발생시키는 데이터 구조 및 로직을 개선
특정 hash key에 너무 큰 데이터가 저장되고 있는 것을 확인했고,
배포 시점에 이 데이터를 hgetall 명령어로 한번에 가져오는 로직이 있는 것을 확인했습니다.
key에 저장된 데이터를 나누는 작업 후, 충분한 검증을 거친 후에 상용 서버에 반영할 계획입니다.
'개발 > AWS' 카테고리의 다른 글
| AWS RDS INSERT문 중복 실행으로 인한 DeadLock 파악 (0) | 2023.03.22 |
|---|---|
| AWS EC2Local port 고갈 인한 서비스 장애 (0) | 2023.03.13 |
| AWS ElastiCache Evictions로 인한 데이터 삭제 (0) | 2023.02.02 |
| AWS ElastiCache 엔진 마이너 버전 업데이트로 인한 다운타임 (0) | 2023.01.31 |
| AWS RDS Too many max_connections 장애 (0) | 2023.01.31 |